Sayısal Sinyal İşleme 2 - Uyarlanır Filtreler ve Aktif Gürültü Yoketme
22 Mar 2020
Reading time ~14 minutes
Emre: Apple Airpods’lar aktif gürültüyü nasıl yokediyor?
Kaan: Sinyal işlemenin en zevkli konularından biridir. Gel birlikte bakalım nasıl oluyormuş.
Problem - Aktif Gürültü Yoketme
İstenmeyen bir gürültünün belirli bir bölgede akustik olarak bastırılmasına Aktif Gürültü Kontrolü deniliyor. Bunu başarmak için genellikle bir ya da birden fazla hoparlörden gürültüyle aynı genlikte fakat ters fazda bir sinyal (anti-gürültü) basılır. Gürültü ve anti-gürültü havada adeta bir toplama işleminden geçerek birbirini yok eder. Bunun sebebi aynı genlikte fakat ters fazda iki dalganın aynı yönde hareket etmesi durumunda fiziksel olarak birbirini söndürmesidir. Bunu temsili olarak şöyle gösterebiliriz.
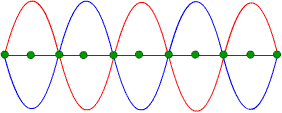
Figürde gördüğün yeşil noktalar havada gerçekleşen toplama (söndürmenin) sonucu olarak hep “sıfır” çıkacaktır.
Ancak eğer fazlar tam olarak denk gelmiyorsa aksine gürültü artabilir de!
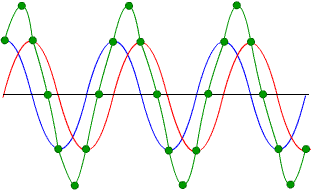
Gördüğün üzere bu kez yeşil noktalar orjinal sinyalden bile büyük genlikte bir sinyal gösteriyor.
Peki bu gürültü sinyalinin tersini oluşturma işi o kadar kolay mıdır?
Tahmin edeceğin üzere elbette değil.
Emre: Neden?
Çünkü istenmeyen gürültü sinyali sürekli aynı genlik ve fazda gelmez. Sesin yayıldığı kaynaktan gürültüyü yoketmeye çalıştığımız bölgeye kadar havada adeta bilinmeyen fiziksel bir kanaldan (ortamdaki yansımalar vs.) geçer. Bu nedenle bu bilinmeyen kanalı modellememiz gerekir. Modelin doğruluğunu ve bu havada gerçekleşen toplama işleminin gerçekten sıfırla sonuçlandığını takip eden uyarlanır bir filtreye ihtiyacımız var. Model doğruysa kaynağa yakın bir referans mikrofonundan aldığımız sinyali bu modelden geçirip, tersini alarak hata mikrofonu civarında hoparlöre verirsek, hata mikrofonu etrafında sessiz bir bölge oluşturabiliriz.
Böylece aktif gürültü yoketme yapan bir sistemin düzeneğini şuna benzer olacaktır:
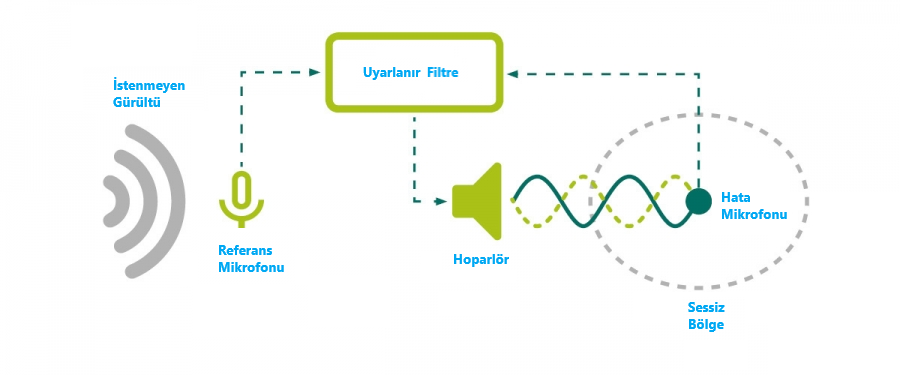
Peki tam olarak nedir bu uyarlanır filtre? Matematiksel olarak nasıl modeller bu havadaki kanalı?
Uyarlanır (Adaptif) Filtre Tasarımı
Temel FIR Filtre
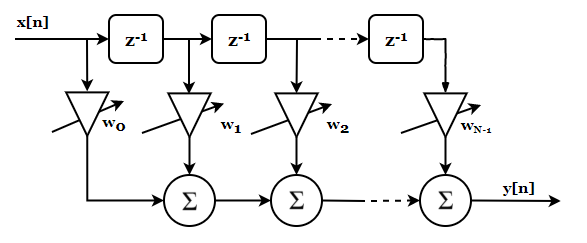
Önce uyarlanabilir olmayan temel filtreyi bir hatırlayalım. Elimizde girişi $x(n)$ ve çıkışı $y(n)$ olan bir sayısal filtre olduğunu düşünelim. Bu filtrenin birim darbe cevabı sonlu sayıda örnek içersin. Böyle bir filtre şöyle bir fark denklemiyle açıklanabilir:
\[y[n] = \sum_{i=0}^{K} w_i x[n-i]\]Bu tür filtrelere Sonlu Dürtü Yanıtlı (SDY) - (finite impulse responda - FIR) filtreler denilir. Bu konu kendi içinde derin bir konu. Ancak şu kadarını söylemem lazım ki, bu filtreleri cazip yapan iki şey var. Birincisi, her zaman doğrusal fazda olmaları. İkincisi de, kutupları olmadığı için her zaman kararlı olmaları. Neden bunların önemli olduğunu anlatabilmek için bu filtre tipinin $z$ ve Fourier dönüşümü özelliklerinden bahsetmem gerekir. Bu detaya burada girmeyeceğim, temel bir konu olduğu için başka kaynaklardan araştırmanı tavsiye ederim. Ancak yine de burada SDY filtreden uyarlanabilir filtreye nasıl gittiğimizi anlatmaya çalışacağım.
Şimdi yukarıdaki işlemi bir konvolüsyon operasyonu olarak düşünerek şu şekilde ifade edebileceğimizi söyleyeceğim ve sen de bu konu hakkında yazılı birçok kitaba güvenerek bana inanacaksın (nihayetinde her alt başlığın detayına girmek istemiyorum- ama bunun ne olduğunu bilmiyorsan diğer kaynaklara bakıp devam etmende fayda var):
\[y[n] = x[n] \circledast w[n]\]Bu denklem aslında doğrusal bir FIR (sonlu dürtlü yanıtlı) filtrenin ayrık zamanda ifadesidir. Dikkat et $x$ ile $w$ arasındaki çarpma değil bir konvolüsyon işlemi. Bu filtrenin $z$ domenindeki temsili gösterimi şöyledir:
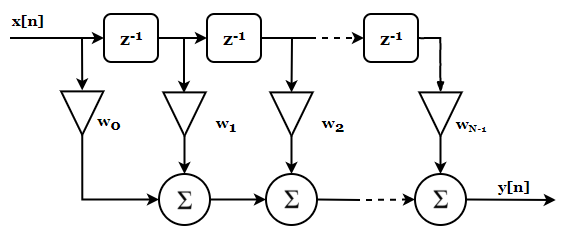
$x$ girişine ait ayrık örnekler birer birer kaydırılarak (figürde gösterilen $z^{-1}$ kendisine gelen ayrık örneği zamanda bir kez geciktirir, yani $x[n]$ girer, $x[n-1]$ çıkar) $w$ ağırlıklarıyla çarpılır ve her kaydırmada bu ağırlıklara denk gelen tüm çarpımlar toplanır. Bu toplamdan çıkan değer sistemin çıkışıdır artık.
Yani aslında bu figürün gösterdiği işlemi yaparsak;
\[y[n] = w_0x[n] + w_1x[n-1] + ... + w_{N-1}x[n-N]\]ifadesini elde ederiz.
Buraya kadarki kısım ayrık zamanlı filtre tasarımında lisans düzeyinde anlatılan genel geçer bilgilerden ibaret. Bir hatırlatma veya bilmiyorsan da altyapı olsun diye anlattım.
Peki bu filtreleri nasıl uyarlanır hale getirebiliriz?
Uyarlanır Filtre
Basit aslında. Filtre katsayılarını yani $w$’ları değiştirirsek elimizdeki filtrenin darbe cevabını da değiştirmiş oluruz değil mi?
Ama bunu neden yapalım?
Bunun birkaç ilginç nedeni olabilir. Mesela bilinmeyen bir sistemi modellemeye çalışıyor olabiliriz.
Bunun için önce elimizdeki filtrenin katsayılarını değişebilir olarak hayal etmemiz lazım.
artık $w$ katsayıları değişebiliyor. Ama neye göre değiştireceğiz? Bilinmeyen bir sistemi modellediğimizde bu katsayıların ne olması lazım?
İşte bunun için bir algoritmaya ihtiyacımız var. Birazdan geliştireceğimiz algoritmayı kullanarak bilinmeyen sistemle elimizdeki filtreyi birbirine benzetmeye çalışacağız. Aradaki farkı sıfırlayınca ya da sıfıra çok yakın bir hale getirdiğimizde elimizdeki filtrenin artık bilinmeyen sistem gibi davrandığını düşünebiliriz. Yani sistemin çalışan bir modeli olacak elimizde. Bu fikri de görselleştirelim:
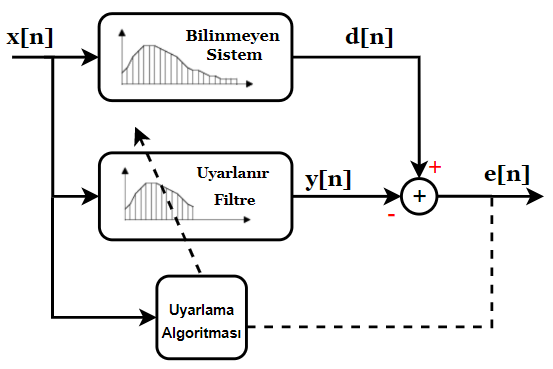
Matematiksel bakış açısından şunu söyleyebiliriz, uyarlama algoritması hatayı sıfıra indirmeyi başarırsa (sıfıra tam inmeyecektir ama yeterince yaklaşabilir) uyarlanabilir filtrenin transfer fonksiyonu modellemeye çalıştığımız bilinmeyen sistemin transfer fonksiyonuna eşit olacaktır. O noktadan itibaren uyarlanır filtrenin katsayıları artık güncellenmez. Ancak bilinmeyen sistem zamanla değişebilir. Bu durumda da uyarlanır filtre yine kendini güncelleyecektir.
İşte aktif gürültü yoketme işinde yukarıda bahsettiğimiz bilinmeyen sistemleri böyle modelleyeceğiz. Bu fikri görüntü işlemede bulanık belirleme, haberleşmede kanal kestirimi, kontrol sistemlerinde sistem belirleme, ters-sistem belirleme, gürültü giderme ya da tahmin işlerinde sıkça kullanılırken bulabilirsin.
Peki öyleyse hatayı sıfıra indiren algoritma nasıl olabilir?
En-Küçük Kareler
Uyarlanır filtrelerin tasarımı temel olarak En-Küçük Kareler tekniğine dayanır.
Bu teknik $Ax=b$ şeklinde ifade edilen artık-belirtilmiş (over determined) doğrusal bir denklem setini çözmek için kullanılır. Bunun sebebi basittir; çünkü tüm doğrusal sistemler $Ax=b$ şeklinde ifade edilebilir. Burada $A$ bir matris, $b$ ve $x$ birer sütun vektörüdür. Amacımız elimizde $A$ ve $b$ varken $x$’i elde etmektir.
$A$ matrisimizin boyutu $m \times n$’dir. $m>n$ olduğu durumlarda elimizde bilinmeyen sayısından çok denklem var demektir ki bu da aslında bu doğrusal denklem setini en küçük hata ile sağlayan tek bir $x$ çözümü var demektir.
Bu doğrusal denklem setini lineer cebirsel olarak şöyle gösteririz:
Basitçe şunu söyleyebilirim ki, bulmaya çalıştığımız çözüm aslında aşağıdaki
farkı minimize ettiğimizde ortaya çıkıyor. Bu farkı minimize etmek aslında hata vektörünün, $\hat{e}$, enerjisini minimize etmeye denk gelir. Böyle çift $|$ işaretiyle gösterilmesine de L-2 normu (Öklitçi yaklaşımla karesini aldığımızdan) denilir. Laplas ya da farklı normlara da bakabilirdik ama bunlar buranın konusu değil.
Probleme geometrik açından da bakabiliriz. $b$ vektörünü $A$ matrisinin sütun uzayı üzerinde gösterebiliriz. Aşağıdaki figürden de görebileceğin üzere $b$ vektürü $A$ matrisinin boş-uzayındadır (sütun uzayında değildir). Yani $A$ matrisinin sütunlarının hiçbir kombinasyonu bize $b$’yi vermez. Ancak yaklaşık bir çözüm bulabiliriz. $b$ vektörüyle $A$ matrisinin sütun uzayı arasındaki en kısa mesafe bizim hata vektörümüzdür.
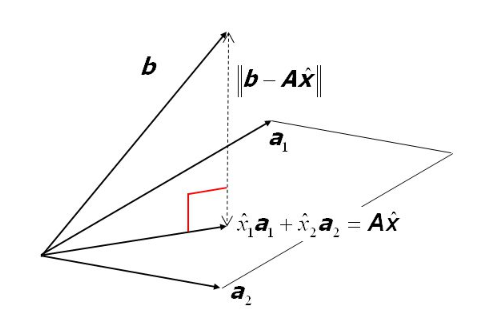
Not: Bu figür Ordinary Least-Squares sunumundan.
O zaman geometrik olarak şunu söyleyebiliriz, çözüm ancak ve ancak $b$ vektörünün $A$’nın sütun uzayı üzerindeki ortogonal projeksiyonuna eşittir.
En küçük kareler yaklaşık çözümü ararken $A$’nın sütun vektörleri arasında hata vektörümüzü minimum yapan seti bulmaya çalışıyoruz ki, $A\hat{x}$ noktası $C(A)$ sütun uzayındaki tüm noktalardan sütun uzayına daha yakındır.
O noktayı bulduğumuzda artık $\hat{x_1}$ ve $\hat{x_2}$ doğrusal denklem takımının çözümüdür. Umarım bu sana sezgisel bir anlayış sağlamıştır.
Geometrik diğer bir yorum da hata performans yüzeyinin şekliyle ilgilidir. $\hat{e}$’nin $n$ boyutlu $x$ vektörüne göre çizimi bize $n+1$ boyutlu bir hiper-parabol verir. $x$’in tek boyutlu olduğu durumda sadece bir elemanı vardır ve yüzey basit bir paraboldür. İki boyutlu durumda paraboloid olur bu yüzey ve bundan büyük boyutları çizmek mümkün değildir. Aslında bu parabolu doğrusal regresyon‘da hata analizi kısmında konuşmuştuk hatırlarsan.
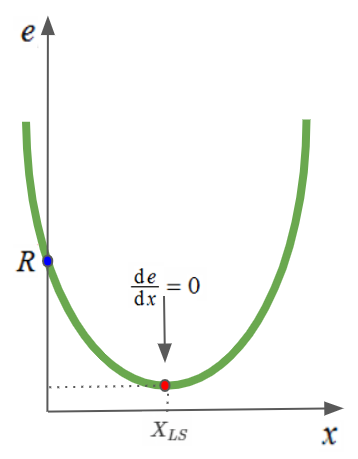
Emre: $R$ nereden geldi?
Kaan: Güzel soru. Bakalım nereden gelmiş.
$A$’nın $2 \times 1$’lik bir matris olduğu duruma bakalım. O zaman yukarıda sözü geçen $e$ vektörünü şöyle hesaplayabiliriz:
Şimdi bu ifadenin içindeki bazı terimleri yeniden isimlendirelim;
\[P = (a_1^2 + a_2^2) \\ Q= (a_1b_1+a_2b_2) \\ R=(b_1^2+b_2^2)\]Bu geometrik yorumu ya da lineer cebirsel çözümü takip edersen, en-küçük kareler çözümünün şöyle çıkacağını göreceksin:
\[X_{LS} = (A^TA)^{-1}A^Tb = \frac{Q}{2 \times P}\]Gördüğün üzere $e$ hata denkleminde $x$’in sıfır olduğu yerde parabol $e$ eksenini $R$’de kesiyor.
İşin ilginç yanı $Ax=b$’nin çözümüne dair başka olasılıklar da var. Eğer sistem eksik-belirtilmiş (denklem sayısından çok bilinmeyen sayısı varsa), o zaman tek bir çözümü yoktur. Tekil Değer Çözümlemesi (singular value decomposition) yöntemi kullanılarak yeterince iyi bir çözüm bulunabilir.
Eğer bilinmeyen sayısı denklem sayısına eşitse, o zaman işimiz daha da kolay. Çözüm direk;
\[X_{LS} = A^{-1}b\]olacaktır.
Bütün bunların bizim filtremizle ne ilgisi mi var?
Yukarıda bahsettiğim Sonlu Dürtü Yanıtlı filtreyi de bu şekilde ifade edebiliriz.
\[Xw = y\]Umarım aradaki benzerliği kurabilmişsindir.
Burada dikkatini mühendisliğin ilginç bir yönüne çekmek istiyorum. Bir probleme matematiksel olarak bambaşka açılardan bakabiliyoruz. Bazen çözüme ulaşmak için her bir açıyı denememiz gerekebilir. Örneğin FIR filtresini bir fark denklemi olarak yazdık, sonra bir konvolüsyon işlemi olarak gördük, $z$ domeninde modelledik ve şimdi de aynı denklemi lineer cebirsel olarak doğrusal denklem sistemi olarak yazıyoruz.
Wiener-hopf Çözümü ve Bilinmeyen Sistem Modelleme
Artık En-küçük Kareler tekniğinin doğrusal bir denklem takımını nasıl çözdüğünü biliyoruz. Bundan faydalanarak uyarlanır filtremizi tasarlayabiliriz.
Yukarıda bilinmeyen sistem ve uyarlanır filtrenin birlikte olduğu bir mimari göstermiştim. Bilinmeyen sistemle uyarlanır filtrenin çıkışı bir fark işlemine tabi tutularak hatayı buluyorduk. Yani
\[e[n] = d[n]-y[n]\]demiştik.
Bu kez de yapmak istediğimiz şey bu hatayı minimize eden katsayıları bulmak.
Bunu yapabilmek için $x[n]$ ve $d[n]$ sinyallerini istatistiksel olarak biraz inceleyip üzerinde düşünmemiz lazım. Eğer $x[n]$ ve $d[n]$ geniş-anlamda durağan süreçlerse ve birbirleriyle ilintili (correlated) ise hata sinyalinin karelerinin ortalamasını minimize edebiliriz ki, bu çözüme Wiener-hopf çözümü denir.
Hatırlatayım, bir rasgele sürecin istatistikleri yani ortalaması ve öz-ilinti fonksiyonu zamanla değişmiyorsa bu süreç geniş-anlamda durağan bir süreçtir.
Filtrenin çıkışının konvolüsyon sonucunun;
\[y[n] = \sum_{k=0}^{N} w_k x[n-k] = \textbf{w}^T\textbf{x}[n]\]olduğunu varsayalım. Wiener-hopf çözümüne ulaşmak için hatanın, $e[n]$ karesini alabiliriz; karesini aldığımız ifadede denklemin her iki tarafının da beklenen değerini alırsak ortalama karesel hatayı (mean square error- MSE) bulabiliriz. Bu ortalama karesel hatayı minimize ederek çözümü bulabiliriz.
\[E\{e^2[n]\}=E\{(d[n]-y[n])^2\}=E\{d^2[n]\}+w^TE\{x[n]x^T[n]\}w-2w^TE\{d[n]x[n]\}\]Bu ifadenin içinde gördüğün $E{x[n]x^T[n]}$ ‘yi $N \times N$ ‘lik ilinti matrisi $\textbf{R}$ ve $E{d[n]x[n]}$’de $N \times 1$’lik çapraz-ilinti fonksiyonu $\textbf{p}$ olarak tanımlarsak.
\[R = E\{x[n]x^T[n]\}\\ p = E\{d[n]x[n]\}\]O zaman ortalama karesel hatayı şöyle ifade edebiliriz:
\[\zeta = E\{d[n]^2\} +\textbf{w}^T\textbf{R}\textbf{w}-\textbf{w}\textbf{w}^T\textbf{p}\]İşin güzel yanı şu ki, yukarıdaki denklem $\textbf{w}$’ya göre kuadratiktik yani sadece bir tane minimum noktası vardır. Öyleyse en küçük ortalama karesel hata (minimum mean squared error- MMSE) çözümü ($\textbf{w}_{opt}$), gradyan (kısmi türev) vektörünü sıfıra eşityelerek bulunabilir:
\[\nabla = \frac{\partial \zeta}{\partial \textbf{w}} = 2\textbf{R}\textbf{w}-2\textbf{p} = 0 \\ \textbf{w}_{opt}=\textbf{R}^{-1}\textbf{p}\]Evet, şu anda ortala karesel hatayı minimize eden katsayıları bulan denkleme bakıyorsun!
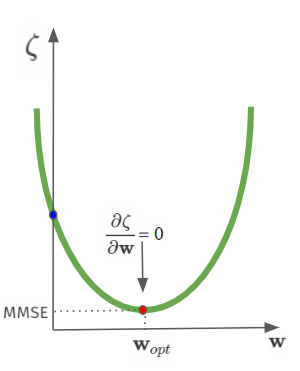
Gördüğün üzere Wiener-hopf çözümünde bir geribesleme yok! Yani hata vektörünü çözümde göremiyoruz. Ama yukarıda çizdiğimiz mimaride katsayıları güncelleyen algoritmaya bir geribesleme vardı.
Bunun nedeni şu; $\textbf{R}$ matrisi terslenebildiği sürece sistem kararlıdır. Bu nedenle aslında $x[n]$ ve $d[n]$ verilerinden sadece ilinti matrisi $\textbf{R}$’yi ve çapraz ilinti fonksiyonu $\textbf{p}$’yi hesaplamak optimal filtre katsayılarını bulmak için yeterli aslında.
Ancak sorun şu ki, $\textbf{R}$’nin hesaplanması için $N$ uzunluğundaki bir filtre için ve $M$ sayıda örnekle $2 \times M \times N$ çarpma-ve-toplama (multiply-and-accumulate - MAC) işlemi gerekir. Ardından $\textbf{R}$’nin terslenmesi $N^3$ çarpma-ve-toplama ve son olarak çapraz ilinti fonksiyonu ile çarpımı $N^2$ çarpma-ve-toplama işlemi gerektirir. Yani tek aşamalı Wiener-hopf algoritmasının işlem yükü $N^3 + N^2 + 2MN$’dir. Bu işlem yükü malesef gerçek zamanlı uygulamalar yapmak için çok fazladır. Daha da kötüsü, eğer $x$ ve $d$’nin istatistikleri değişirse filtre katsayıları yeniden hesaplanmalıdır. Yani algoritmanın takip etme özelliği de yoktur. Sonuç olarak Wiener-hopf pratik değildir. Benzeri bir analizi En-küçül Kareler çözümü için de söyleyebiliriz. Veri boyu arttıkça matris boyutları çok büyür. Büyüyen matris boyları $A$ matrisinin tersinin alınmasını işlem yükü açısından çok zorlaştırır.
Buradan bir çıkış yok mu?
Her zamanki gibi, elbette var.
Hata enerjisini minimize etmek isteyen gerçek zamanlı sistemler en-küçük ortalama kareler (least-mean-squares) veya özyineli en-küçük kareler (recursive least squares) gibi gradyan iniş tabanlı uyarlanır algoritmalar kullanır.
Gradyan iniş algoritmasından Bayesçi Çıkarım ve Doğrusal Regresyon üzerine konuşurken bahsetmiştik.
En-küçük Ortalama Kareler (LMS)
En baştan şunu söyleyeyim; LMS algoritması bazı şartlar sağlandığında Wiener-hopf çözümüne yakınsar. Aslında burada da yine ortalama karesel hata performans yüzeyini oluşturuyoruz. Ancak bu kez kapalı form Wiener-hopf çözümü yerine gradyan inişi tabanlı bir çözüm uyguluyoruz.
Algoritmanın özeti şöyle; hiper-parabol üzerinde herhangi bir noktadan başlarız, filtre katsayılarını en dik gradyanın ters yönünde değiştiririz ve yakınsaklığa ulaştıp ulaşmadığımızı kontrol ederiz. Ulaştıysak algoritma sonlanır, yoksa gradyanı değiştirme adımına geri döneriz.
Hata performans yüzeyinin gradyanını hatırlayalım:
\[\nabla_k = \frac{\partial E\{e^2[n]\}}{\partial \textbf{w}[n]} = 2\textbf{R}\textbf{w}[n]-2\textbf{p}\]Bu durumda gradyan iniş algoritması şöyledir:
\[\textbf{w}[n+1] = \textbf{w}[n]+\mu(-\nabla_n)\]Burada $\mu$’yü ilk kez gördün. Sen sormadan ben söyleyeyim $\mu$ bizim gradyan hesapladıkça ilerlemeyi kabul ettiğimiz adım aralığı. Bu adım aralığı uyarlamanın hızını ve yakınsaklık anındaki hatanın teorik olana (MMSE) yakınlığını belirliyor. $\mu$’yü küçük seçerek küçük sıçramalarla optimum noktaya ilerlenebilir. Adım büyüklüğü küçük olduğundan yakınsama yavaş olacaktır ama yine de optimum nokta civarında küçük adımlarla dolaşınca teoriye en yakın noktada algoritma sonlandırılarak başarılı bir kestirim yapılabilir. Adım aralığı büyük tutulunca hızlıca yakınsama sağlanabilir ancak bu kez de optimum noktaya yakın yerlerde büyük sıçramalar yapacağımızdan optimum noktaya yaklaşmak zor olacaktır.
Herneyse, burada bir sorun gözüne çarpmadı mı?
Emre: Çarpmaz mı! Biz $\textbf{R}$ ve $\textbf{p}$’yi hesaplamak çok işlem yükü alıyor diye yeni bir yöntem arıyorduk. Yine bunlara bağlı bir algoritma bulduk sanki. Performans yüzeyini hesaplamanın maliyeti yine yüksek değil mi?
Kaan: Tam üstüne bastın!
$\textbf{R}$ ve $\textbf{p}$’yi hesaplama işinden kurtulmanın bir yolunu bulmamız lazım.
Bunun için gerçek gradyan yerine “anlık” gradyan kestirimi yapabiliriz! Bunu yapmanın bir yolu gradyanı hesaplarken hatanın karesinin beklenen değeri (ortalaması) yerine sadece o anki değerinin karesini kullanmaktır.
\[e[n] = d[n] - y[n] = d[n]-\textbf{w}^T[n]\textbf{x}[n] \\ \frac{\partial e[n]}{\partial \textbf{w}[n]}=-\textbf{x}[n] \\ \hat {\nabla_n} = \frac{\partial e^2[n]}{\partial \textbf{w}[n]} = 2e[n]\frac{\partial e[n]}{\partial \textbf{w}[n]}=-2e[n]\textbf{x}[n]\]Öyleyse gradyanın anlık kestirimi kullanılarak filtre güncellemesi şu şekilde yapılabilir:
\[\textbf{w}[n+1] = \textbf{w}[n]+\mu(-\nabla_n) = \textbf{w}[n] + 2\mu e[n]\textbf{x}[n]\]Hepsi bu. LMS algoritmasını uygulamak işlem yükü açısından basittir. Adım başına FIR filtreyi uygulamak için $N$ adet çarpma-ve-toplama (MAC) ve filtreyi güncellemek için de $N$ adet MAC işlemi gerekir.
O zaman uyarlanır filtremizin son haline bir bakalım:
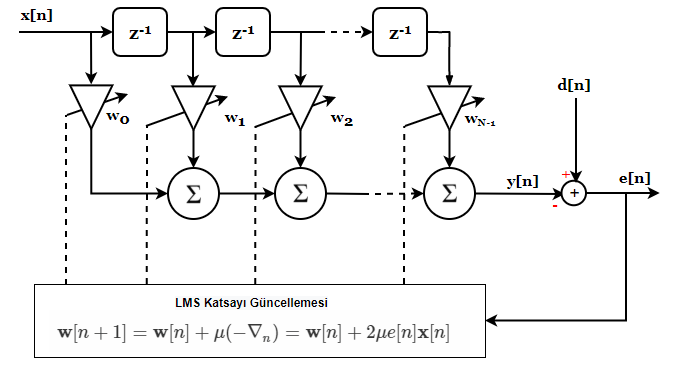
Algoritma tasarımının önemli bir aşaması uyarlanır filtre boyuna karar vermektir. Uzun filtreler sistemi daha iyi modeller ancak bu da işlem yükünü artırır.
İkinci parametre de adım aralığıdır. Hem hızlıca yakınsamayı hem de algoritmayı kararsız hale getirmeyecek şekilde seçilmesi gerekir. Genellikle uygulanan bir seçim şöyledir:
Bu denklemde $E{x^2[n]}$’i giriş sinyalinin gücü olarak yorumlayabilirsin.
Öyleyse LMS algoritmasının özetini bir daha gösterelim:
Aktif Gürültü Yoketme
Şimdi yukarıda tanımladığımız algoritmayı kodlayarak aktif gürültü yoketmenin bir jet uçağı gürültüsü üzerinde nasıl çalıştığına bakalım. Jet gürültüsünü thebeautybrains.com‘dan indirebilirsiniz.
import numpy as np
from scipy.signal import lfilter
from scipy.io import wavfile
import matplotlib.pyplot as plt
# iterasyon sayisi
N=10000
# Jet içi gürültü kaydını yükleyelim
fs, signal = wavfile.read('insidejet.wav')
y = np.copy(signal)
# giriş sinyal kaydı 8 bit olduğu için 256'ya normalize edelim
x = np.true_divide(y, 256)
# filtre katsayılarını oluşturalım
ind = np.arange(0,2.0,0.2)
p1 = np.array(np.zeros(50)).transpose()
p2 = np.array([np.exp(-(x**2)) for x in ind]).transpose()
p = np.append(p1,p2)
p_normalized = [x/np.sum(p) for x in p]
p_len = len(p_normalized)
# x giriş sinyali üzerinde FIR filtreleme yapalım
d = lfilter(p, [1.0], x)
# uyarlanır filtre katsayılarını ilklendirelim
w_len = p_len
w = np.zeros(w_len)
# sinyal gücü ve iterasyon sayısına bakarak adım aralığını bulalım (1/(N*E[x^2])'nin iki katı makul)
mu = 2/(N*np.var(x))
error_array = []
# uyarlanır filtre algoritmasını çalıştıralım
for i in range(w_len, N):
x_ = x[i:i-w_len:-1]
e = d[i] + np.array(w.T).dot(x_)
w = w - mu * 2 * x_ * e
error_array.append(e)
f1 = plt.figure()
f2 = plt.figure()
ax1 = f1.add_subplot(111)
ax1.plot(p)
ax1.set_title('Birincil yol (primary path) filtre katsayıları')
ax2 = f2.add_subplot(111)
ax2.plot(error_array)
ax2.set_title('Jet içi gürültüsü - Uyarlanır Filtre hata eğrisi')
ax2.set(xlabel='iterasyon', ylabel='e')
plt.show()
Bu algoritmayı çalıştırınca ortaya çıkacak hata eğrisi aşağıdaki gibi olacak:
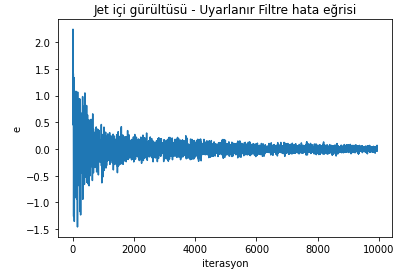
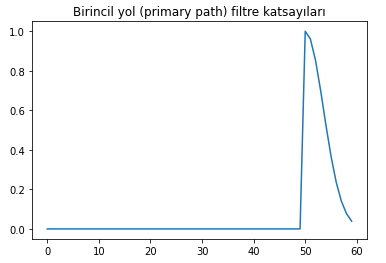
Tasarladığımız birincil yok (primary path) filtre katsayıları da şöyle olacaktır:
Gerçek Hayat
Simülasyonları olduğu şekilde bir Sayısal Sinyal İşleyici (digital signal processor- DSP) üzerinde gerçeklersen göreceksin ki teorik haliyle çalışmayacak. Bunun iki sebebi var. Birincisi, hoparlörden çıkan anti-gürültü akustik olarak referans mikrofonuna ulaşıp referans olarak ölçtüğümüz sinyali bozabilir.
İkinci olarak da, uyarlanır filtrenin çıkışındaki elektriksel sinyal hoparlörden çıkana kadar ve hata sinyali de mikrofondan elektriksel olarak okunup işlemciye ulaşana kadar iki farklı sistemden geçer. Bu problemlerin de hesaba katılması lazım.
Gerçek hayatta Filtered-x Least Mean Square (Fx-LMS) ya da RLS (Recursive Least Squares) algoritmaları kullanılmaktadır. Bu algoritmalar hem daha hızlı yakınsayan hem de daha az işlem gücüne ihtiyaç duyan algoritmalar. İleri seviyede bu işle uğraşmak istiyorsan bu kadar sezgisel ve teorik bilgiden sonra bu algoritmalara da bakabilirsin.
Bir de gerçek dünya problemlerinde genellikle birden fazla referans mikrofonu ve birden fazla hoparlörlü (çok kanallı) aktif gürültü yoketme sistemleri geliştiriliyor. Çok kanallı AGY’nin matematiği de şimdiye kadar baktıklarımızdan çok farklı değil. Temel olarak bu bahsi anladıysan, çok kanallı çözümü anlatan literatürü de kolayca anlayabilirsin.
Referanslar
- Adaptive Filter Theory, Simon Haykin
- İşaret İşlemede İleri Konular, Ders Notları, Fatih Kara
- Jet ses kayıtları
- What is Column Space? — Example, Intuition & Visualization